Java基础
Java特点
面向对象(封装,继承,多态);
平台无关性( Java 虚拟机实现平台无关性);
可靠性(具备异常处理和自动内存管理机制);
编译与解释并存;
Java 强大的生态;
和c++区别?
-
Java 不提供指针来直接访问内存,程序内存更加安全
-
Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
-
Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
-
C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载。
基本数据类型
用 new 创建对象(特别是小的、简单的变量)并不是非常有效,因为new 将对象置于“堆”里。对于这些类型,Java 采纳了与 C 和 C++相同的方法。也就是说,不是用 new 创建变量,而是创建一个并非句柄的“自动”变量。这个变量容纳了具体的值,并置于栈中,能够更高效地存取。
boolean
char(16)
byte(8)、short(16)、int(32)、long(64)
float(32)、double(64)
对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。
- 如果 boolean 是 “单独使用”:boolean 被编译为 int 类型,占 4 个字节
- 如果boolean 是以 “boolean 数组” 的形式使用:boolean 占 1 个字节,Java 虚拟机直接支持 boolean 数组,通过
newarray指令创建 boolean 数组,然后通过 byte 数组指令baload和bastore来访问和修改 boolean 数组
这八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean 。
基本类型和包装类型的区别?
- 用途:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
- 存储方式:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被
static修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。 - 占用空间:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
- 默认值:成员变量包装类型不赋值就是
null,而基本类型有默认值。 - 比较方式:对于基本数据类型来说,
==比较的是值。对于包装数据类型来说,==比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用equals()方法。
包装类型的缓存机制
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 TRUE or FALSE。
对于 Integer,可以通过 JVM 参数 -XX:AutoBoxCacheMax=<size> 修改缓存上限,但不能修改下限 -128。实际使用时,并不建议设置过大的值,避免浪费内存,甚至是 OOM。
对于Byte,Short,Long ,Character 没有类似 -XX:AutoBoxCacheMax 参数可以修改,因此缓存范围是固定的,无法通过 JVM 参数调整。
Boolean 则直接返回预定义的 TRUE 和 FALSE 实例,没有缓存范围的概念。
两种浮点数类型的包装类 Float,Double 并没有实现缓存机制。
Integer 缓存源码:
Character 缓存源码:
Boolean 缓存源码:
BigInteger 和 BigDecimal
我们在使用 BigDecimal 时,为了防止精度丢失,推荐使用它的BigDecimal(String val)构造方法或者 BigDecimal.valueOf(double val) 静态方法来创建对象,valueOf内部执行toString方法。
使用 divide 方法的时候尽量使用 3 个参数版本,并且RoundingMode 不要选择 UNNECESSARY,否则很可能会遇到 ArithmeticException(无法除尽出现无限循环小数的时候),其中 scale 表示要保留几位小数,roundingMode 代表保留规则。
BigDecimal大小比较应使用compareTo()方法,而不是equals()方法。因为 equals() 方法不仅仅会比较值的大小(value)还会比较精度(scale),而 compareTo() 方法比较的时候会忽略精度。
BigInteger 内部使用 int[] 数组来存储任意大小的整形数据。
BigDecimal 底层实现是 BigInteger 。
运算符
赋值:
对基本数据类型的赋值是非常直接的。直接将来自一个地方的内容复制到另一个地方。
但在为对象“赋值”的时候,情况却发生了变化。对一个对象进行操作时,我们真正操作的是它的句柄。所以倘若“从一个对象到另一个对象”赋值,实际就是将句柄从一个地方复制到另一个地方。
算术运算符:
中包括加号(+)、减号(-)、除号 (/)、乘号(*)以及模数(%,从整数除法中获得余数)
取模:本质:a % b = a - a / b * b。a为小数,则:a % b = a - (int)a / b * b
移位运算符:
左移位运算符(<<)能将运算符左边的运算对象向左移动运算符右侧指定的位数(在低位补 0)。
“有符号”右移位运算符(>>)则将运算符左边的运算对象向右移动运算符右侧指定的位数。“有符号”右移位运算符使用了 “符号扩展”:若值为正,则在高位插入 0;若值为负,则在高位插入1。
Java 也添加了一种“无符号”右移位运算符(>>>),它使用了“零扩展”:无论正负,都在高位插入0。
若对char,byte 或者short 进行移位处理,那么在移位进行之前,它们会自动转换成一个 int。
使用移位运算符的主要原因
- 高效:移位运算符直接对应于处理器的移位指令。现代处理器具有专门的硬件指令来执行这些移位操作,这些指令通常在一个时钟周期内完成。相比之下,乘法和除法等算术运算在硬件层面上需要更多的时钟周期来完成。
- 节省内存:通过移位操作,可以使用一个整数(如
int或long)来存储多个布尔值或标志位,从而节省内存。
可变参数
- java中允许将同一个类中多个同名同功能但参数个数不同的方法,封装成一个方法。通过可变参数实现
-
可变参数的实参可以是0个或任意多个
-
可变参数实参可以是数组,可变参数的本质就是数组
-
可变参数可以和普通类型的参数一起放在形参列表,但必须保证可变参数在最后
-
一个形参列表只能出现一个可变参数
访问修饰符
| 访问级别 | 修饰符 | 本类 | 同包 | 子类 | 不同包 |
|---|---|---|---|---|---|
| 公开 | public | √ | √ | √ | √ |
| 受保护 | protected | √ | √ | √ | × |
| 默认 | √ | √ | × | × | |
| 私有 | private | √ | × | × | × |
修饰符 public 表示对所有类可⻅。
修饰符 protected 表示对同⼀包内的类和所有⼦类可⻅。⼦类可以访问⽗类中声明为 protected 的成员, ⽽不管⼦类与⽗类是否在同⼀包中。
如果没有使⽤任何访问修饰符(即没有写 public 、 protected 、 private ),则默认为包级别访问。这意味着只有同⼀包中的类可以访问。
修饰符 private 表示对同⼀类内可⻅。私有成员只能在声明它们的类中访问
修饰符可以用来修饰属性,成员方法和类,只有默认和public才能修饰类
面向对象
面向过程编程(POP):面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。
面向对象编程(OOP):面向对象会先抽象出对象,把类或对象作为基本单元来组织代码。
封装
将对象的字段和方法封装在一个类中,并通过访问控制来隐藏对象的内部实现细节。外部不能直接访问对象的内部数据,只能通过提供的公共方法来操作数据。
继承
继承是一种机制,允许子类继承父类的属性和方法,通过继承,子类可以复用父类的代码,并可以在子类中扩展或重写父类的方法。可以提高代码的重用,程序的可维护性,节省大量创建新类的时间 ,提高我们的开发效率。
- 子类继承了所有属性和方法,但是私有属性和方法不能在子类直接访问,要通过父类公共的方法
- 子类必须调用父类的构造器完成父类的初始化
- 当创建子类的对象时,默认总会去调用父类的无参构造器,如果父类没有提供无参构造器,则必须在子类的构造器中用
super(参数列表);去指定使用父类的哪个构造器完成父类的初始化工作,否则编译不会通过。 super()和this()都只能放在构造器第一行,因此不能共存在一个构造器- 所有类都是
Object类的子类 - 子类只能继承一个父类,即单继承机制
| 区别点 | this | super |
|---|---|---|
| 访问属性 | 访问本类中属性,如果没有从父类中继续查找 | 从父类开始查找属性 |
| 调用方法 | 访问本类中方法,如果没有从父类中继续查找 | 从父类开始查找方法 |
| 调用构造器 | 调用本类构造器,必须放在首行 | 调用父类构造器,必须放在首行 |
| 特殊 | 表示当前对象 | 子类中访问父类对象 |
多态
指同一个方法或对象在不同场景下可以表现出不同的行为。Java中主要通过重载和重写实现。
多态的具体表现:
- 方法的多态:
- 重写:子类重写父类的方法
- 重载:同一个类中可以有多个同名方法,但参数列表不同
- 对象的多态:
- 一个对象的编译类型(对象类型)和运行类型(引用类型)可以不一致
- 编译类型在定义对象时就确定了,不能改变
- 运行类型是可以变化的
- 编译类型看等号左边,运行类型看等号右边
| 区别点 | 重载方法 | 重写方法 |
|---|---|---|
| 发生范围 | 同一个类 | 父子类 |
| 参数列表 | 必须修改 | 一定不能修改 |
| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
| 异常 | 可修改 | 子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等; |
| 访问修饰符 | 可修改 | 一定不能做更严格的限制(可以降低限制) |
| 发生阶段 | 编译期 | 运行期 |
(重写)两同两小一大:
- 两同:方法名、参数列表相同
- 两小:重写方法的返回值和抛出异常类型要和被重写方法的相同或是其子类。
- 一大:修饰符 >= 被重写方法的修饰符
深拷贝和浅拷贝
浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
引用拷贝:引用拷贝就是两个不同的引用指向同一个对象。
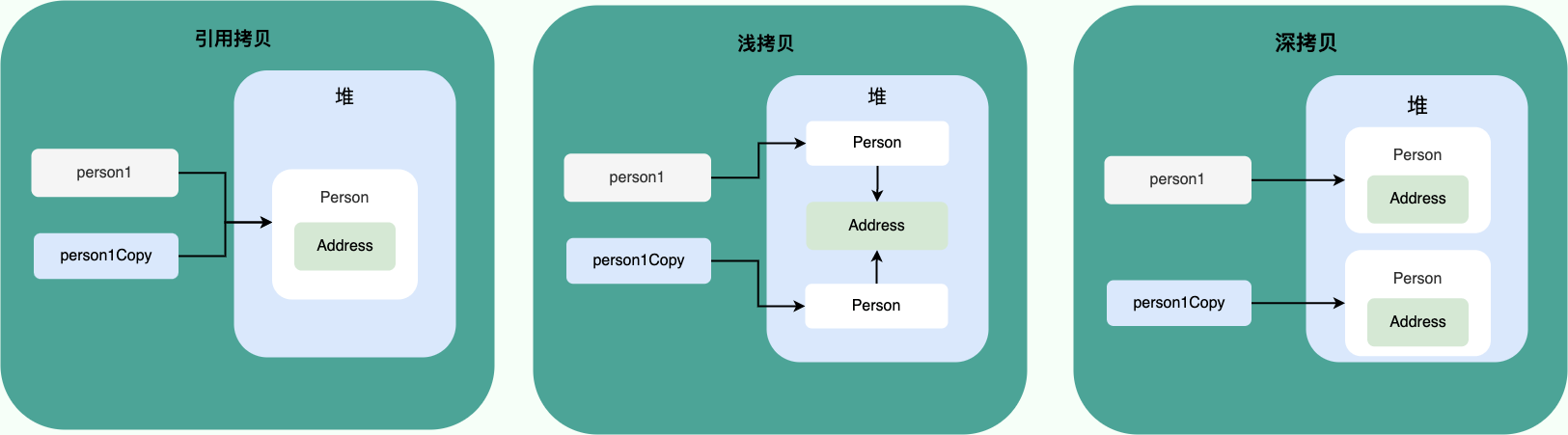
Object类
Object 类是一个特殊的类,是所有类的父类。
==运算符
- 对于基本数据类型来说,
==比较的是值。 - 对于引用数据类型来说,
==比较的是对象的内存地址。
equals方法
- 不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。
- 默认判断地址是否相等,子类往往重写该方法,用于判断内容是否相等
static
类变量/静态变量
static变量被对象所共享,在类加载的时候就生成-
静态变量保存在class实例的尾部,而class对象保存在堆中
-
生命周期为类加载到类消亡
类方法/静态方法
静态方法是不在对象上执行的方法,没有隐式参数,没有this(非静态方法中,this指向这个方法的隐式参数)。不能在对象上执行操作,但是对象可以调用静态方法,建议使用类名调用静态方法
当方法中不涉及任何对象相关的成员或一些通用的方法,可以设计成静态方法提高开发效率
- 类方法和普通方法都随着类加载而加载,将结构信息存储到方法区
- 类方法中不允许使用和对象有关的关键字,如
this和super - 静态方法只能访问静态变量或静态方法,非静态方法可以访问静态成员和非静态成员
静态方法为什么不能调用非静态成员?
这个需要结合 JVM 的相关知识,主要原因如下:
- 静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,需要通过类的实例对象去访问。
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。
静态代码块
类加载时执行并且只执行一次
静态内部类
静态成员可以被类直接访问,而不需要创建类实例;而静态成员无法直接访问非静态类,因为非静态成员依赖类实例。
main方法
- main方法是虚拟机调用,访问权限必须是public
- 执行main方法时不必创建对象,所以必须是static
- 接收String类型的数组形参,保存运行时传递的参数
- main方法中可以直接使用所在类的静态属性和静态方法;访问非静态成员,必须创建对象去调用
代码块
代码块又叫初始化块,在加载类或创建对象时隐式调用
-
修饰符只能选
static,分别称为静态代码块和普通代码块。静态代码块随类的加载而执行,只执行一次,而普通代码块每创建对象都会执行 -
静态代码块只能调用静态成员,普通代码块可以调用任意成员
- 好处:
- 相当于另一种形式的构造器,可以做初始化操作,代码块的调用优先于构造器
- 如果多个构造器中都有重复语句,可以抽取到代码块中,提高复用性
类什么时候加载?
-
创建对象实例(new)
-
创建子类对象实例,父类也会被加载
-
使用类的静态成员时
创建一个对象时,在一个类调用顺序
- 调用静态代码块和静态属性初始化(多个则按照定义顺序)
- 普通代码块和普通属性初始化
- 调用构造方法。构造器的最前面其实隐藏了
super()和调用普通代码块
创建一个子类对象时,调用顺序
- 父类的静态代码块和静态属性
- 子类的静态代码块和静态属性
- 父类的普通代码块和普通属性初始化
- 父类的构造方法
- 子类的普通代码块和普通属性初始化
- 子类的构造方法
final
final数据:
对于基本数据类型,final 会将值变成一个常数;但对于对象句柄,final 会将句柄变成一个常数。进行声明时,必须将句柄初始化到一个具体的对象。而且永远不能将句柄变成指向另一个对象。然而,对象本身是可以修改的。Java 对此未提供任何手段,可将一个对象直接变成一个常数。这一限制也适用于数组,它也属于对象。
final数据必须赋初值,以后不能修改,初始化位置:
- 定义时
- 在构造器中
- 在代码块中
final方法:
之所以要使用final 方法,可能是出于对两方面理由的考虑。第一个是为方法“上锁”,防止任何继承类改变它的本来含义。设计程序时,若希望一个方法的行为在继承期间保持不变,而且不可被覆盖或改写,就可以采取这种做法。
采用final 方法的第二个理由是程序执行的效率。将一个方法设成 final 后,编译器就可以把对那个方法的所有调用都置入“嵌入”调用里。只要编译器发现一个final 方法调用,它会用方法主体内实际代码的一个副本来替换方法调用。这样做可避免方法调用时的系统开销。当然,若方法体积太大,那么程序也会变得雍肿,可能受到到不到嵌入代码所带来的任何性能提升。因为任何提升都被花在方法内部的时间抵消了。Java 编译器能自动侦测这些情况,并颇为“明智”地决定是否嵌入一个 final 方法。
通常,只有在方法的代码量非常少,或者想明确禁止方法被覆盖的时候,才应考虑将一个方法设为 final。
类内所有private 方法都自动成为final。由于我们不能访问一个 private 方法,所以它绝对不会被其他方法覆盖。
final类:
将类定义成 final 后,结果只是禁止进行继承——没有更多的限制。然而,由于它禁止了继承,所以一个 final 类中的所有方法都默认为final。因为此时再也无法覆盖它们。所以与我们将一个方法明确声明为final 一样,编译器此时有相同的效率选择。
抽象类和接口
接口和抽象类的共同点
- 实例化:接口和抽象类都不能直接实例化,只能被实现(接口)或继承(抽象类)后才能创建具体的对象。
- 抽象方法:接口和抽象类都可以包含抽象方法。抽象方法没有方法体,必须在子类或实现类中实现
接口和抽象类的区别
- 设计目的:接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
- 继承和实现:一个类只能继承一个类(包括抽象类),因为 Java 不支持多继承。但一个类可以实现多个接口,一个接口也可以继承多个其他接口。
- 成员变量:接口中的成员变量只能是
public static final类型的,不能被修改且必须有初始值。抽象类的成员变量可以有任何修饰符(private,protected,public),可以在子类中被重新定义或赋值。 - 方法
- Java 8 之前,接口中的方法默认是
public abstract,也就是只能有方法声明。自 Java 8 起,可以在接口中定义default(默认) 方法和static(静态)方法。 自 Java 9 起,接口可以包含private方法。 - 抽象类可以包含抽象方法和非抽象方法。抽象方法没有方法体,必须在子类中实现。非抽象方法有具体实现,可以直接在抽象类中使用或在子类中重写。
内部类
一个类的内部又完整的嵌套了另一个类结构,被嵌套的类称为内部类。内部类最大的特点是可以直接访问外部类的属性,并且可以直接体现类之间的包含关系。
实际上内部类是一个编译层面的概念,像一个语法糖一样,经过编译器之后其实内部类会提升为外部顶级类,和外部类没有区别。
局部内部类
类似局部变量,定义在外部类的局部位置,在方法、代码块中,有类名
- 不能添加访问修饰符,因为它的地位是一个局部变量,局部变量是不能使用修饰符的。但可以使用final修饰
- 只能访问final变量和形参
- 作用域:仅仅在定义它的方法或代码块中
- 如果外部类和内部类重名时,默认遵守就近原则,如果想访问外部类的成员,则可以用
外部类名.this.成员访问
匿名内部类
定义在外部类的局部位置,比如方法中,没有类名,同时还是一个对象
一个接口/类的方法的某个实现方式在程序中只会执行一次,但为了使用它,我们需要创建它的实现类/子类去实现重写。此时可以使用匿名内部类的方式,可以无需创建新的类,减少代码冗余。
-
匿名内部类既是一个类的定义,同时也是一个对象,只能创建匿名内部类的一个实例
-
没有构造器,没有静态资源
-
可以访问外部类的所有成员,包括私有的
- 不能添加修饰符和static,因为它的地位就是一个局部变量
- 作用域:仅仅是在定义它的方法或代码块中
- 外部其他类不能访问匿名类
-
如果外部类和内部类重名时,默认遵守就近原则,如果想访问外部类的成员,则可以用
外部类名.this.成员访问 -
可以当作实参直接传递,简洁高效
成员内部类
- 定义在外部类的成员位置,并且没有static修饰
- 可以直接使用外部类的所有成员,包括私有成员
- 可以添加任意的访问修饰符,因为它的地位是一个成员
- 本身内部不能有静态属性,因为自己本身就需要依靠外部类的实例化
- 作用域:和外部类的其他成员一样,为整个类体
- 外部其他类访问内部类
外部类名.内部类名 对象名 = 外部类名.new 内部类名();外部类名.内部类名 对象名 = 外部对象.get();new 外部类名().new 内部类();
静态内部类
类似类的静态成员属性
- 定义在外部类的成员位置,有static修饰
- 可以访问外部类所有静态成员,不能访问非静态成员
- 可以添加任意修饰符
- 作用域:整个类体
- 外部其他类访问内部类
- 通过类名直接访问,但要满足访问权限
-
get方法
-
如果外部类和内部类重名时,默认遵守就近原则,如果想访问外部类的成员,则可以用
外部类名.成员访问
枚举类
实现:
- 构造器私有化
- 对外暴露对象
public final static - 提供get方法,不提供set方法
细节:
-
使用
enum代替class声明枚举类,就不能继承其他类了(因为隐式继承Enum类,java是单继承机制),但是可以继承接口 -
使用
enum关键字开发一个枚举类时,默认会继承Enum类, 而且是一个final类 - 枚举简化为
枚举对象(参数列表) - 使用无参构造器创建枚举对象,则实参和小括号都可以省略
- 当有多个枚举对象时,使用
,分隔,最后一个;结尾 - 枚举对象必须放在枚举类首行
异常

Exception 和 Error 都是继承了 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
Error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如 OutOfMemoryError 之类,都是 Error 的子类。
Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Exception 又分为可检查(checked)异常和不检查(unchecked)异常。
-
可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。如果受检查异常没有被
catch或者throws关键字处理的话,就没办法通过编译。 -
不检查异常就是所谓的运行时异常,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
编译时异常(可检查异常):
- 数据库操作异常 SQLException
- 文件操作异常 IOException
- 文件不存在 FileNotFoundException
- 类不存在 ClassNotFoundException
- 文件末尾发生异常 EOPException
- 参数异常 IllegalArguementException
运行时异常(不检查异常): 1. 空指针异常 NullPointerException 2. 数学运算异常 ArithmeticException 3. 数组下标越界异常 ArrayIndexOutOfBoundsException 4. 类型转换异常 ClassCastException 5. 数字格式不正确异常 NumberFormatException
try-catch-finally:
try块:用于捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。
catch块:用于处理 try 捕获到的异常。
finally 块:无论是否捕获或处理异常,finally 块里的语句都会被执行。
可以有多个catch语句,捕获不同的异常,要求父类异常在后,子类异常在前,比如Exception在后,NullPointException在前,如果发生异常,只会匹配一个catch
可以进行try-finally配合使用,相当于没有捕获异常,因此程序会直接奔溃。应用场景:执行一段代码不管是否发生异常都必须执行某个业务逻辑
finally子句中包含return语句时肯产生意想不到的结果,finally中的return语句将会覆盖原来的返回值。不要把改变控制流的语句(return, throw, break, continue)放在finally子句中
throws:将异常抛出,交给调用者处理,最顶级的处理者是JVM
编译异常程序中必须处理,运行时异常程序中没有处理默认是throws
子类重写父类的方法时,对抛出异常的规定:子类重写的方法抛出的异常类型要么和父类抛出的异常一致,要么为父类抛出异常类型的子类型。
在throws过程中,如果有try-catch,相当于处理异常,就可以不必throws
自定义异常:异常类名 extends Exception/RuntimeException如果继承Exception,属于编译异常;如果继承RuntimeException,属于运行异常,一般继承RuntimeException
| 意义 | 位置 | 后面跟的东西 | |
|---|---|---|---|
| throws | 异常处理的一种方式 | 方法声明处 | 异常类型 |
| throw | 手动生成异常对象关键字 | 方法体中 | 异常对象 |
try-with-resources语句:
当try退出时会自动调用 res.close()
finally总是会被执⾏吗?
⼀般来说, finally 块都会在 try 或 catch 块执⾏完毕后被执⾏,即使发⽣了异常。然⽽,有⼀些情况下 finally 块可能不会执⾏,主要是在以下情况:
- 在 try 或 catch 块中调⽤了 System.exit() : 调⽤ System.exit() 会导致Java虚拟机(JVM)退出, 此时 finally 块中的代码不会被执⾏。
- 在 try 块中发⽣了死循环: 如果在 try 块中发⽣了⽆限循环或者其他永远不会结束的操作, finally 块 可能⽆法执⾏。
- 程序所在线程死亡或关闭CPU
注意:
- 尽量不要捕获类似Exception这样的异常,而是捕获特定的异常。
- 不要吞了异常,最好输入到日志中
- 不要延迟处理异常,否则堆栈信息会很多
- try-catch范围尽可能小
- 不要通过异常来控制程序流程
- 不要在finally代码块中处理返回值或者直接return
String、StringBuffer、StringBuilder
String
有属性private final char value[], value赋值后不可以修改,指不能指向新的地址,但单个字符内容可以改变。在 Java 9 之后,String、StringBuilder 与 StringBuffer 的实现改用 byte 数组存储字符串,不同编码占用字节不同:为了节省空间。
String 真正不可变有下面几点原因:
- 保存字符串的数组被
final修饰且为私有的,并且String类没有提供/暴露修改这个字符串的方法。拼接、裁剪字符串等动作,都会产生新的 String 对象。 String类被final修饰导致其不能被继承,进而避免了子类破坏String不可变。
String 中的 equals 方法是被重写过的,比较的是 String 字符串的值是否相等。 Object 的 equals 方法是比较的对象的内存地址。
StringBuffer
解决了String大量拼接字符串时产生许多无用的中间对象问题,提供append和add等方法,可以将字符串添加到已有序列的末尾或指定位置。
本质是一个线程安全的可修改的字符序列,把所有修改数据的方法都加上synchronized ,保证了线程安全。
StringBuilder
和StringBuffer本质上没什么区别,就是去掉了保证线程安全的那部分,减少了开销。
StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中使用char数组保存字符串(JDK9以后是byte数组),不过没有使用 final 和 private 关键字修饰,是可变的,构建时初始字符串长度加 16。
总结:
- String(不可变,线程安全)
- StringBuffer(可变、线程安全)
- StringBuilder(可变、⾮线程安全)
操作少量的数据: 适用 String
单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
泛型
泛型的好处:
- 程序更加易读
- 安全性有所保证
注意:
-
类型参数不支持基本类型,只支持引用类型,这是因为泛型会被擦除为具体类型,而Object不能存储基本类型的值。
-
不能实例化泛型数组,因为类型擦除会将数组变为Object数组,如果允许实例化,极易造成类型转换异常。
-
给泛型指定类型后,可以传入该类型或其子类类型
-
如果不指定泛型,默认是Object
-
泛型没有继承性
List<Object> list = new ArrayList<String>();//错误
泛型类
注意细节:
- 普通方法和属性可以使用泛型
- 静态方法和属性中不能使用泛型。因为静态是和类相关的,类加载时对象还没有创建
- 泛型类的类型,是在创建对象时确定的
- 如果创建对象时没有指定类型,默认Object
泛型接口
注意细节:
- 接口中静态成员也不能使用泛型
- 泛型接口的类型,是在继承接口或实现接口时确定的
- 没有指定泛型默认Object
泛型方法
注意细节:
- 泛型方法可以定义在普通类中,也可以定义在泛型类中
- 当泛型方法被调用时,类型会确定
- public void eat(E e){}不是泛型方法,而是使用了泛型
通配符
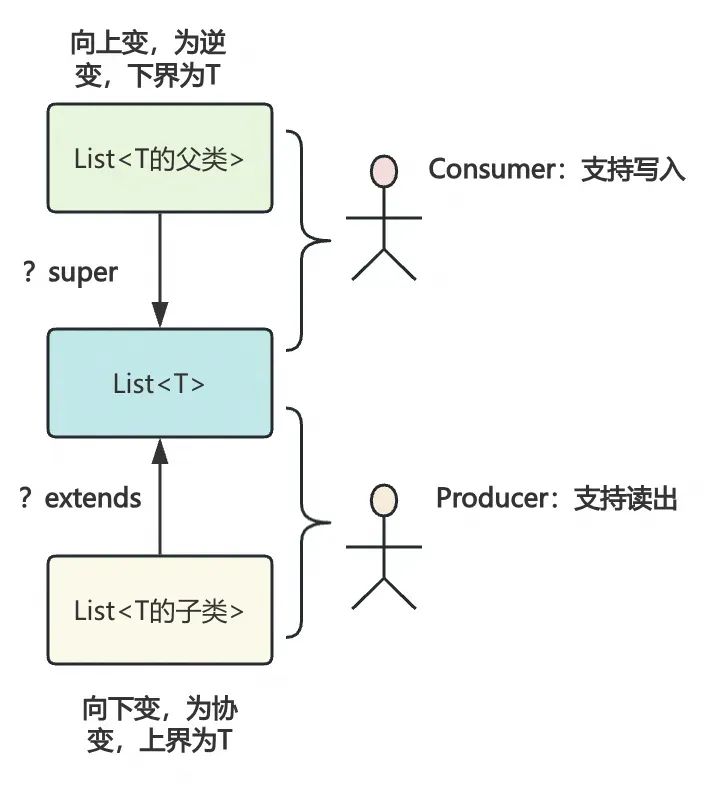
PECS
Producer Extends,Consumer Super(生产者使用 extends,消费者使用 super)。
使用 ? extends 的组合来声明一个泛型的上界,表示只能是指定类型或是其子类。当集合是“生产者”,即从集合中读取数据时,使用 extends。这样可以从集合中读取类型为 T 或其子类的对象,但不能往集合中添加null外的新对象,因为确切的类型不确定。
使用 ? super 的组合来声明一个泛型的下界,来表示可以接收本类型或者其父类型。由于最多只能接收父类型泛型,所以不会有类型转换失败的风险,因此可以添加元素,不过添加的元素类型只能是指定类型和其子类。读取元素时将不能确定具体的类型,只能用Object来接收。
泛型擦除:
虚拟机没有泛型类型对象,Java语言中的泛型只在程序源码中存在,在编译后的字节码文件中,全部泛型都被替换为原来的裸类型,并且在相应的地方插入了强制转型代码,因此对于运行期的Java语言来说,ArrayList<Integer> 与 ArrayList<String> 其实是同一个类型。
在泛型类或泛型方法中,所有的类型参数都会在编译时被擦除:
- 如果泛型类型参数没有指定上界,编译器会将其替换为
Object。 - 如果泛型类型参数指定了上界(例如
<T extends Number>),编译器会将其替换为上界类型(这里是Number)。
序列化和方序列化
序列化:将数据结构或对象转换成可以存储或传输的形式,通常是二进制字节流,也可以是 JSON, XML 等文本格式
反序列化:将在序列化过程中所生成的数据转换为原始数据结构或者对象的过程
序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
比较常用的序列化协议有 Hessian、Kryo、Protobuf好
JDK自带的序列化
JDK 自带的序列化,只需实现 java.io.Serializable接口即可。
serialVersionUID 有什么作用?
序列化号 serialVersionUID 用来验证序列化和反序列化对象的ID是否一致的。反序列化时,会检查 serialVersionUID 是否和当前类的 serialVersionUID 一致。如果 serialVersionUID 不一致则会抛出 InvalidClassException 异常。强烈推荐每个序列化类都手动指定其 serialVersionUID,如果不手动指定,那么编译器会动态生成默认的 serialVersionUID。
Java序列化不包含静态变量?
Java序列化机制只会保存对象的实例变量的状态,而不会保存静态变量的状态。
静态变量是类级别的变量,它们被所有类的实例共享。序列化的主要目的是保存和恢复对象的实例状态,以便在不同的时间或不同的环境中能够重建对象。由于静态变量不是实例的一部分,它们的值在类加载时就已经初始化并存在,因此它们不需要被序列化和恢复。
serialVersionUID 不是被 static 变量修饰了吗?为什么还会被“序列化”?
static 修饰的变量是静态变量,本身是不会被序列化的。但是,serialVersionUID 的序列化做了特殊处理,在序列化时,会将 serialVersionUID 的值写入到序列化的二进制字节流中;在反序列化时,也会解析它并做一致性判断。
如果有些字段不想进行序列化怎么办?
对于不想进行序列化的变量,可以使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
IO流
字节流
InputStream(字节输入流):
-
FileInputStream是一个比较常用的字节输入流对象,可直接指定文件路径,可以直接读取单字节数据,也可以读取至字节数组中。不过,一般我们是不会直接单独使用FileInputStream,通常会配合BufferedInputStream -
DataInputStream用于读取指定类型数据,不能单独使用,必须结合其它流,比如FileInputStream。 ObjectInputStream用于从输入流中读取 Java 对象(反序列化),ObjectOutputStream用于将对象写入到输出流(序列化)。用于序列化和反序列化的类必须实现Serializable接口,对象中如果有属性不想被序列化,使用transient修饰。
OutputStream(字节输出流):
FileOutputStream是最常用的字节输出流对象,可直接指定文件路径,可以直接输出单字节数据,也可以输出指定的字节数组。类似于FileInputStream,FileOutputStream通常也会配合BufferedOutputStream(字节缓冲输出流,后文会讲到)来使用。DataOutputStream用于写入指定类型数据,不能单独使用,必须结合其它流,比如FileOutputStream。ObjectInputStream用于从输入流中读取 Java 对象(ObjectInputStream,反序列化),ObjectOutputStream将对象写入到输出流(ObjectOutputStream,序列化)
字符流
Reader(字符输入流):
InputStreamReader 是字节流转换为字符流的桥梁,其子类 FileReader 是基于该基础上的封装,可以直接操作字符文件。
Writer(字符输出流):
OutputStreamWriter 是字符流转换为字节流的桥梁,其子类 FileWriter 是基于该基础上的封装,可以直接将字符写入到文件。
字节缓冲流
BufferedInputStream 从源头(通常是文件)读取数据(字节信息)到内存的过程中不会一个字节一个字节的读取,而是会先将读取到的字节存放在缓存区,并从内部缓冲区中单独读取字节。这样大幅减少了 IO 次数,提高了读取效率。
BufferedInputStream 内部维护了一个缓冲区,这个缓冲区实际就是一个字节数组。缓冲区的大小默认为 8192 字节
BufferedOutputStream 类似于 BufferedInputStream
字符缓冲流
BufferedReader (字符缓冲输入流)和 BufferedWriter(字符缓冲输出流)类似于 BufferedInputStream(字节缓冲输入流)和BufferedOutputStream(字节缓冲输入流),内部都维护了一个字节数组作为缓冲区。
打印流
System.out 实际是用于获取一个 PrintStream 对象,print方法实际调用的是 PrintStream 对象的 write 方法。
PrintStream 属于字节打印流,与之对应的是 PrintWriter (字符打印流)。PrintStream 是 OutputStream 的子类,PrintWriter 是 Writer 的子类。
随机访问流
随机访问流指的是支持随意跳转到文件的任意位置进行读写的 RandomAccessFile 。
RandomAccessFile 比较常见的一个应用就是实现大文件的 断点续传
I/O模型
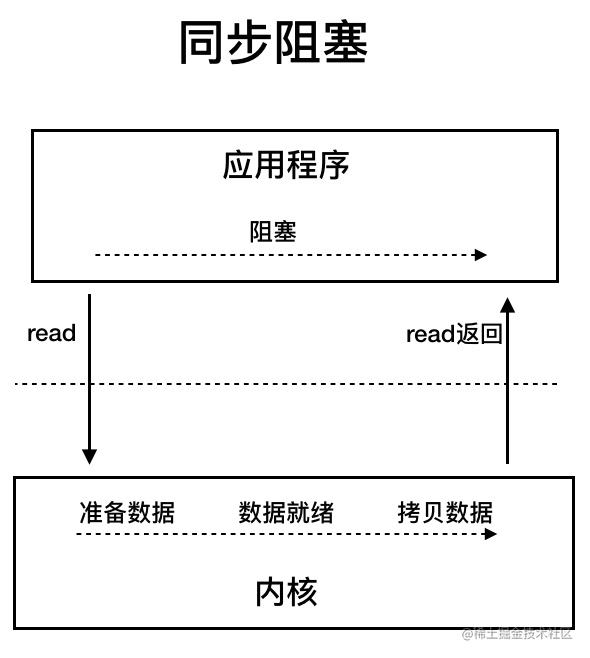
BIO(Blocking I/O):同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
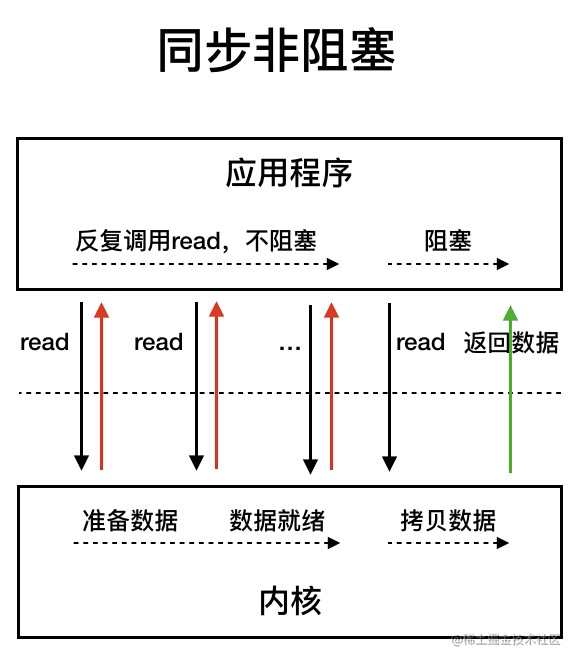
NIO(Non-blocking I/O): 在⾮阻塞 I/O 模型中,线程执⾏⼀个 I/O 操作时不会等待,⽽是继续执⾏其他任务, 这需要通过轮询(polling)或者使⽤回调函数等机制来检查 I/O 操作是否完成。
IO多路复⽤:IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
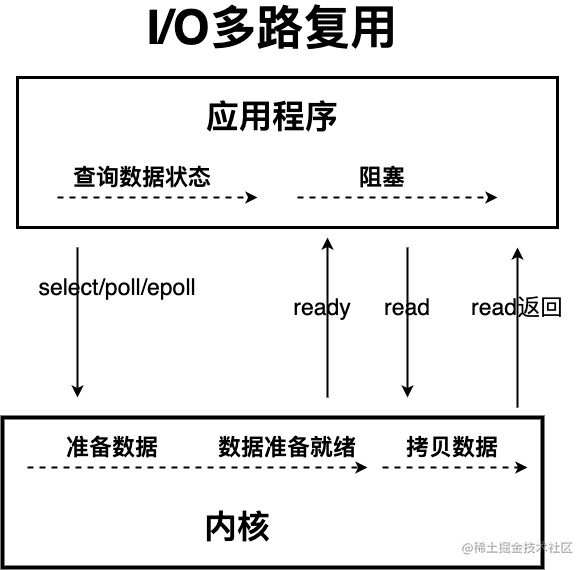
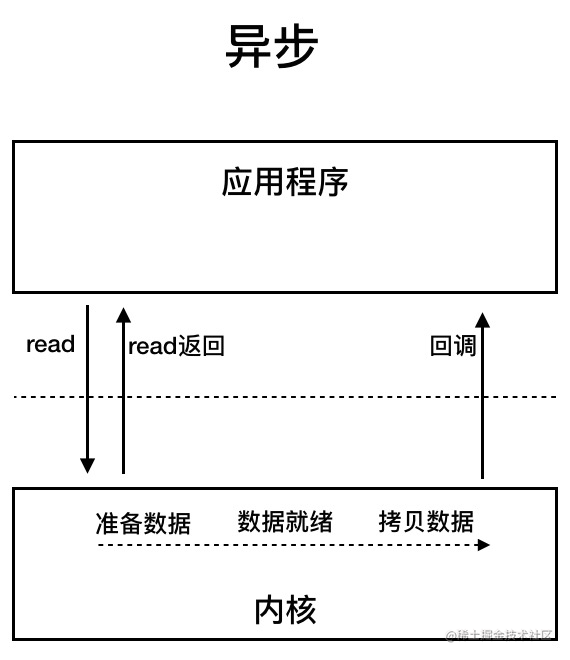
AIO(Asynchronous I/O):异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
反射
反射机制允许程序在执行期间借助于Reflection API取得任何类的内部信息,并能操作对象的属性及方法。
使用场景:
- 框架
- 动态代理
- 注解
反射相关的主要类:
优缺点
优点:可以动态的创建和使用对象(框架底层核心),使用灵活
缺点:使用反射是解释执行,对执行速度有影响,安全问题
反射调用优化:关闭访问检查
Method和Field、Constructor对象都有setAccessible()方法,作用是启动和禁用访问安全检查,参数为true表示反射的对象在使用时取消访问检查,提高反射效率
获取 Class 对象的四种方式
如果我们动态获取到这些信息,我们需要依靠 Class 对象。Class 类对象将一个类的方法、变量等信息告诉运行的程序。Java 提供了四种方式获取 Class 对象:
- 知道具体类的情况下可以使用:
但是我们一般是不知道具体类的,基本都是通过遍历包下面的类来获取 Class 对象,通过此方式获取 Class 对象不会进行初始化
- 通过
Class.forName()传入类的全路径获取:
这种方式会触发类的初始化,静态代码块会被执行
- 通过对象实例
instance.getClass()获取:
- 通过类加载器
xxxClassLoader.loadClass()传入类路径获取:
通过类加载器获取 Class 对象不会进行初始化,意味着不进行包括初始化等一系列步骤,静态代码块和静态对象不会得到执行
通过反射获取类结构信息:
通过反射创建对象方式
- 获取类的构造器
- 使用newInstance(): 调用构造器
通过反射访问类中成员
- 根据属性名获取Field对象 //getField获取public属性, getDeclaredField获取所有类型属性
-
爆破:
f.setAccessible(true) -
访问:
通过反射访问方法
- 根据方法名和参数列表获取Method方法对象
-
获取对象 :
Object targetObject = clazz.newInstance(); -
爆破:
m.setAccessible(true);//私有的需要爆破 -
访问:
Object returnValue = m.invoke(targetObject, 实参列表); //如果是静态方法,o可以写成null
动态代理
动态代理是在运行时动态生成类字节码,并加载到 JVM 中
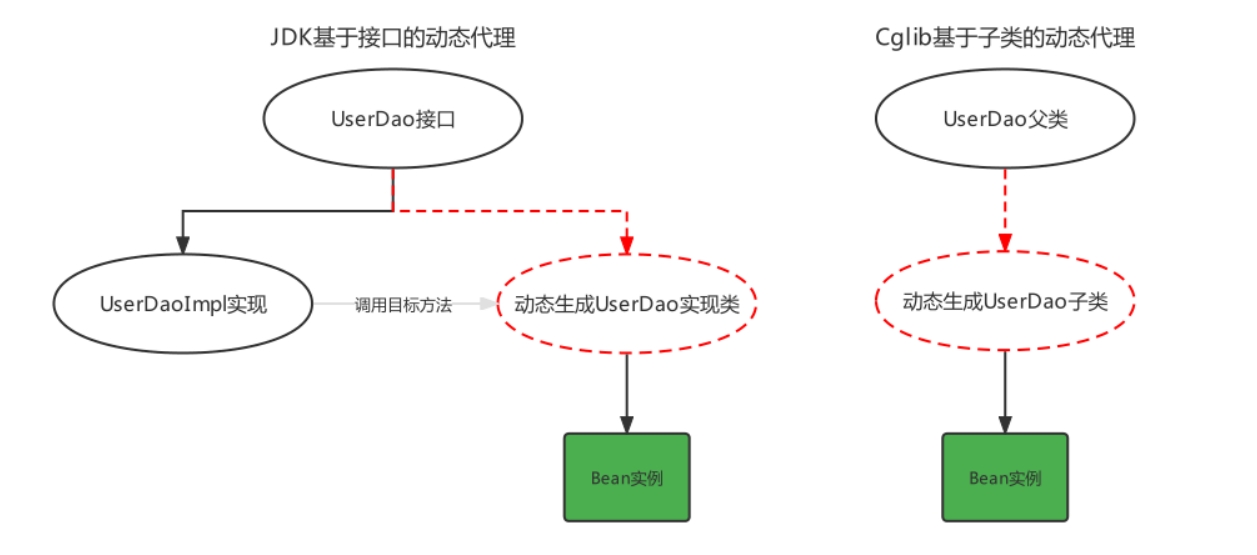
| 代理技术 | 使用条件 |
|---|---|
| JDK 动态代理技术 | 目标类有接口,是基于接口动态生成实现类的代理对象 |
| Cglib 动态代理技术 | 目标类无接口且不能使用final修饰,是基于被代理对象动态生成子对象为代理对象 |
JDK动态代理
基于接口的,代理类一定是有定义的接口,在 Java 动态代理机制中 InvocationHandler 接口和 Proxy 类是核心。
Proxy 类中使用频率最高的方法是:newProxyInstance() ,这个方法主要用来生成一个代理对象。
要实现动态代理的话,还必须需要实现InvocationHandler 来自定义处理逻辑。 当我们的动态代理对象调用一个方法时,这个方法的调用就会被转发到实现InvocationHandler 接口类的 invoke 方法来调用。
通过Proxy 类的 newProxyInstance() 创建的代理对象在调用方法的时候,实际会调用到实现InvocationHandler 接口的类的 invoke()方法。 可以在 invoke() 方法中自定义处理逻辑,比如在方法执行前后做什么事情。
JDK 动态代理类使用步骤:
- 定义一个接口及其实现类;
- 自定义代理类实现
InvocationHandler接口并重写invoke方法,在invoke方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑; - 通过
Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h)方法创建代理对象;
CGLIB 动态代理
CGLIB基于ASM字节码生成工具,它通过继承的方式实现代理类,所以不需要接口,可以代理普通类,但需要注意 final 方法(不可继承)。
在 CGLIB 动态代理机制中 MethodInterceptor 接口和 Enhancer 类是核心。
你需要自定义 MethodInterceptor 并重写 intercept 方法,intercept 用于拦截增强被代理类的方法。
- obj : 代理对象
- method : 被拦截的方法,目标类中的方法
- args : 方法入参
- proxy : CGLIB 提供的一个对象,它可以用来调用被代理类中的原始方法
可以通过 Enhancer类来动态获取被代理类,当代理类调用方法的时候,实际调用的是 MethodInterceptor 中的 intercept 方法。
CGLIB 动态代理类使用步骤:
- 引入依赖
-
定义类
-
自定义
MethodInterceptor并重写intercept方法,intercept用于拦截增强被代理类的方法,和 JDK 动态代理中的invoke方法类似; -
通过
Enhancer类的create()创建代理类;
注解
Java中的注解(Annotation)是一种标记,是一种用于为代码元素(如类、方法、字段等)添加元数据的机制。这些元数据可以在编译时、类加载时或运行时被读取,并用于各种目的,如代码生成、运行时行为控制、配置管理等。注解本质是一个继承了Annotation 的特殊接口
注解可以通过不同的保留策略来决定其在何时可见:
RetentionPolicy.SOURCE:注解仅存在于源代码中,在编译成字节码后丢弃。RetentionPolicy.CLASS:注解保留在编译后的字节码中,但在运行时不可见(默认)。RetentionPolicy.RUNTIME:注解保留在字节码中,并且在运行时可通过反射访问。
定义注解:
@Retention:指定注解的保留策略。上例中,注解在运行时可见。
@Target:指定注解可以应用的代码元素。上例中,注解只能用于方法。
属性:注解的属性类似于无参方法,可以有默认值(如count),也可以不设置默认值(如value)。
获取注解:
Class类
Class类也是类,因此继承Object类
Class类对象不是new出来的,而是系统创建的
对于某个类的Class对象,在内存只有一份,因为类只加载一次
每个类的实例都会记得自己是由哪个Class实例所产生
通过Class对象可以完整的得到一个类的完整结构,通过一系列的API
Class对象存放在堆中
类的字节码二进制数据,是放在方法区的,有的地方称为类的元数据(包括方法代码、变量名、方法名、访问权限等)
获取Class对象的方法 :
SPI机制
SPI 即 Service Provider Interface ,字面意思就是:“服务提供者的接口”,我的理解是:专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。
SPI和API区别:
API是实现方提供接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力 ,这种接口和实现都是放在实现方的。
SPI是接口存在于调用方这边 ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
SPI 机制的具体实现本质上还是通过反射完成的。即:我们按照规定将要暴露对外使用的具体实现类在 META-INF/services/ 文件下声明。
使用步骤:
- 定义服务接口
- 提供服务实现
- 创建服务配置文件:在服务实现的JAR包中,创建
META-INF/services目录,并在其中添加一个配置文件,文件名为服务接口的全限定名,内容为服务实现类的全限定名:
文件内容:
- 加载和使用
语法糖
语法糖的存在主要是方便开发人员使用。 Java 虚拟机并不支持这些语法糖,这些语法糖在编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。
Java 中最常用的语法糖主要有:
-
switch支持String与枚举:Java 中的
switch自身原本就支持基本类型,字符串的 switch 是通过equals()和hashCode()方法来实现的 -
泛型:所有泛型类的类型参数在编译时都会被擦除
-
变长参数:数组
-
条件编译:根据 if 判断条件的真假,编译器直接把分支为 false 的代码块消除。
-
自动拆装箱:装箱过程是通过调用包装器的 valueOf 方法实现的,而拆箱过程是通过调用包装器的 xxxValue 方法实现的
-
内部类:编译后会生成两个不同class文件
-
枚举:当我们使用
enum来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类继承Enum类,所以枚举类型不能被继承 -
断言:断言的底层实现就是 if 语言
-
数值字面量:编译器并不认识在数字字面量中的
_,需要在编译阶段把他去掉 -
for-each:实现原理就是普通for循环和迭代器
-
try-with-resource:编译器帮助关闭资源
-
Lambda表达式:lambda 表达式的实现其实是依赖了一些底层的 api,在编译阶段,编译器会把 lambda 表达式进行解糖,转换成调用内部 api 的方式。
函数式编程
代码简洁,开发快速,易于理解,易于并发编程
Lambda表达式
只关注参数列表和方法体
- 参数类型可以省略
- 方法体中只有一句代码时,大括号、return和代码分号可以省略
- 方法只有一个参数时,小括号可以省略
Stream流
用来对集合或数组进行链状流式的操作
1. 创建流
- 单列集合(Collection):
集合对象.stream() - 数组:
Arrays.stream(数组)或Stream.of(数组) - 双列集合(Map):转换为单列集合后再创建
map.entrySet().stream() - 使用
Stream.builder()创建流,然后使用add方法添加元素,最后使用build方法构建流。使用build后不能再add元素
2. 中间操作:筛选、映射、排序
-
filter:对流中的元素进行条件过滤,符合过滤条件的才能继续留在流中
-
map:对流中的元素进行计算或转换
-
distinct:去除流中的重复元素。依赖Object的equals和hashCode方法判断是否是相同对象
-
sorted:对流中的元素进行排序
-
limit:可以设置流的最大长度,超出的部分将被舍弃
-
skip:跳过流中的前n个元素,返回剩下的元素
-
flatMap:map适合单层结构的流,进行一对一转换。flatMap不仅能够执行map的转换功能,还能扁平化多层数据结构,将其转换合并为一个单层流。
3. 终结操作:查找与匹配、聚合操作、规约操作、收集操作、迭代操作。终结操作会强制执行中间的惰性操作
-
迭代操作:
-
forEach:对流中元素进行任意顺序遍历操作,通过传入参数指定遍历到的元素的具体操作
-
forEachOrdered:按照流中的顺序遍历元素
-
聚合操作:规约操作的特殊形式
-
count:获取当前流中元素个数
-
max,min:获取最值
-
average
-
sum
-
收集操作:collect:把当前流转换为一个集合,使用Collectors工具类
-
List:
Collectors.toList() - Set:
Collectors.toSet() - Map:
Collectors.toMap() - 连接操作收集流中所有字符:
Collectors.joining() - 统计总和、平均值、数量、最值:
Collectors.summarizing(Int|Long|Double) -
分组:
Collectors.grouopingBy(),分类函数是断言函数时(返回boolean的函数)partitioningBy更高效 -
查找与匹配操作:短路操作,匹配一个后就会返回
-
anyMatch:判断是否有任意符合匹配条件的元素,结果为boolean类型
-
allMatch:判断是否都符合匹配条件,结果为boolean
-
noneMatch:判断是否都不符合匹配条件,结果为boolean
-
findAny:获取流中的任意一个元素。无法保证一定获取流中的第一个元素。并行处理流时很有效
-
findFirst:获取流中第一个元素
-
规约操作:reduce:对流中的数据按照自己定制的计算方式计算出一个结果
-
reduce的作用是把stream中的元素给组合起来,我们可以传入一个初始值,它会按照我们定制的计算方式依次拿流中的元素进行计算,结果继续与后面元素计算
-
内部的计算方式
-
要使用并行流,则操作必须是可结合的。且要提供第二个函数来合并处理
注意事项:
- 惰性求值:如果没有终结操作,中间操作是不会执行的
- 流是一次性的:一个流对象经过终结操作后,这个流就不能再被使用
- 不会影响原数据
Optional
可以写出更优雅的代码,避免空指针异常
创建对象:Optional.of(对象)对象不能为空; Optional.ofNullable(对象),无论传入参数是否为null都不会出问题
安全消费值:ifPresent()接受一个函数,如果可选值存在就传递给该函数,否则不发生任何事情;ifPresentOrElse() 接收两个函数
获取值:get() ,获取数据为空时,会空指针异常
安全获取值:
-
orElse(),是否为空都会执行括号里的内容 -
orElseGet(),数据不为空返回数据,数据为空则根据传入的默认值参数返回,为空才执行括号里的内容 orElseThrow(),数据不为空返回数据,数据为空根据传入的参数抛出异常
过滤:filter(),数据不符合要求,返回value为null的Optional对象
判断:isPresent(),更推荐使用ifPresent()
数据转换:map()
基本类型流
用来直接存储基本类型值,无需使用包装类型
存储short、char、byte、boolean可以使用IntStream;float使用DoubleStream。
对象流可以转换为基本类型流:mapToInt、mapToLong、mapToDouble;基本类型流转换为对象流需要使用boxed方法
函数式接口
接口中只有一个抽象方法
JDK函数式接口都加上了@FunctionalInterface注解进行标识,但无论是否有该注解,只要接口中只有一个抽象方法都是函数式接口
常用的默认方法
- and:相当于&&来拼接判断条件
- or:||
- negate:!,取反
方法引用
使用lambda表达式时,如果方法体中只有一个方法的调用的话(包括构造方法),可以使用方法引用进一步简化代码
引用类的静态方法
重写方法的时候,方法体中只有一行代码,这行代码是调用了某个类的静态方法,并且重写的抽象方法中所有参数按照顺序传入了调用的静态方法中
引用对象的实例方法
重写方法的时候,方法体中只有一行代码,这行代码是调用了某个对象的成员方法,并且重写的抽象方法中所有参数按照顺序传入了调用的成员方法中
引用类的实例方法
重写方法的时候,方法体中只有一行代码,这行代码是调用了第一个参数的成员方法,并且重写的抽象方法中剩余的所有参数按照顺序传入了调用的成员方法中
构造器引用
重写方法的时候,方法体中只有一行代码,这行代码是调用了某个类的构造器,并且重写的抽象方法中所有参数按照顺序传入了调用的构造方法中
并行流
parallel() :将任意的顺序流转换为并行流
parallerStream():从集合中获取一个并行流
正则表达式
匹配符
| 符号 | 意义 | 示例 | 解释 |
|---|---|---|---|
| [] | 可接收的字符列表 | [efgh] | efgh中的任意字符 |
| [^] | 不可接收的字符列表 | [^abc] | abc除外的任意字符 |
| - | 连字符 | A-Z | 任意大写字母 |
| . | 匹配除\n之外的任何字符 | a..b | a开头b结尾中间任意两个字符的字符串 |
| \\d | 匹配单个数字字符,相当于[0-9] | \\d{3}(\\d)? | 包含3个或4个数字的字符串 |
| \\D | 匹配单个非数字字符 | \\D(\\d)* | 以单个非数字字符开头,后接任意个数字字符的字符串 |
| \\w | 匹配单个数字、大小写字母字符、下划线 相当于[0-9a-zA-Z] |
\\d{3}\\w{4} | 以3个数字字符开头长度为7的数字字符串 |
| \\W | 匹配单个非数字、大小写字母字符、下划线 相当于[ ^0-9a-zA-Z] |
\\W+\\d{2} | 以至少1个非数字字母字符开头,2个数字字符结尾的字符串 |
| \\s | 匹配任何空白字符(空格、制表符等) | ||
| \\S | 匹配任何非空白字符 | ||
| 选择匹配符 | |||
| | | 选择匹配符,匹配之前或之后的 | ab|cd | ab或cd |
| 限定符 | |||
| * | 指定字符重复0次或n次 | (abc)* | 包含任意个abc的字符串 |
| + | 指定字符重复1次或n次 | m+(abc)* | 以至少1个m开头,后接任意个abc的字符串 |
| ? | 指定字符重复0次或1次 | m+abc? | 以m开头,后接ab或abc的字符串 |
| {n} | 只能输入n个字符 | [abcd]{3} | 由abcd中字母组成的任意长度为3的字符串 |
| {n, } | 指定至少n个匹配 | [abcd]{3, } | 由abcd中字母组成的任意长度至少为3的字符串 |
| {n, m} | 指定至少n个但不多于m个匹配,尽可能匹配多的(贪婪匹配) | [abcd]{3, 5} | 由abcd中字母组成的任意长度至少为3但不大于5的字符串 |
| ? | 非贪婪匹配,限定符后加 ? | \\d+? | 至少一个数字字符的字符串,尽可能匹配少的 |
| 定位符 | |||
| ^ | 指定起始字符 | ^[0-9]+[a-z]* | 以至少1个数字开头,后接任意个小写字母的字符串 |
| $ | 指定结束字符 | ^[0-9]\\-[a-z]+$ | 以1个数字开头后接'-',并以至少一个小写字母结尾的字符串 |
| \\b | 匹配目标字符串的边界 | han\\b | 边界指子串间有空格或是目标字符串的结束位置 |
| \\B | 匹配目标字符串的非边界 | han\\B |
java正则表达式默认区分大小写,实现不区分大小写:
分组
| 常用分组构造形式 | 说明 |
|---|---|
| (pattern) | 非命名捕获。捕获匹配的子字符串,编号为0的第一个捕获是整个正则表达式模式匹配的文本,其他捕获结果根据左括号的顺序从1开始自动编号 |
| (?\<name>pattern) | 命名捕获。将匹配子字符串捕获到一个组名称过编号名称中。用于name的字符串不能包含任何标点符号,并且不能以数字开头,可以使用单引号替代尖括号,例如 ?'name' |
| (?:pattern) | 匹配但是不捕获子字符串,是一个非捕获匹配,不存储供以后使用的匹配。这对于用or字符(|)组合模式部件的情况很有用。例如 'industr(?:y|ies)' 是比 'industry|industries' 更经济的表达式 |
| (?=pattern) | 非捕获匹配。例如,'Windows (?=95|98|NT|2000)' 匹配 "Windows 2000" 中的 "Windows",但是不匹配 "Windows 3.1" 中的 "Windows" |
| (?!pattern) | 非捕获匹配。例如,'Windows (!=95|98|NT|2000' 匹配 "Windows 3.1" 中的"Windows", 但是不匹配"Windows 2000" 中的"Windows" |
反向引用
圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个我们称为反向引用,这种引用既可以是正则表达式内部,也可以是在正则表达式外部,内部反向引用\\分组号,外部反向引用$分组号
特性
java8:
- Lambda 表达式
- stream流
- Optional:解决 NPE(
java.lang.NullPointerException)问题,它就是为 NPE 而生的,其中可以包含空值或非空值
java21:
- switch 表达式增加类型模式来进行匹配
- 虚拟线程
- 简化了main函数的声明